Daha önceki yazımda Influxdb , telegraf ve grafana kurulumunu anlatmıştım, bu yazımda bu 3lüyü Vmware yapılarımızı monitor etmede nasıl kullanacağımızı göstermek istiyorum.
Öncelikle telegraf conf dosyasına giriyoruz,
nano /etc/telegraf/telegraf.conf
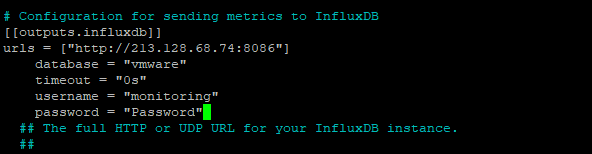
İlgili satır altına sunucu ip adresimizi ve influxdb için oluşturduğumuz user ve passwordu yazıyoruz,
[[outputs.influxdb]]
Tavsiyem var olanlara dokunmayın benim verdiğim satırları kendi user ve ip adresinize göre düzenleyip yapıştırın,
urls = ["http://213.....:8086"] database = "vmware" timeout = "0s" username = "monitoring" password = "Password"
Ardından Vcenter veya ESX metric değerlerini okumak için ilgili satırları girelim,
[[inputs.vsphere]] # List of vCenter URLs to be monitored. These three lines must be uncommented ## and edited for the plugin to work. vcenters = [ "https://Vcenter veya ESX ip adresinizi/sdk" ] username = "User adresiniz" password = "PASS"
## VMs ## Typical VM metrics (if omitted or empty, all metrics are collected) vm_metric_include = [ "cpu.demand.average", "cpu.idle.summation", "cpu.latency.average", "cpu.readiness.average", "cpu.ready.summation", "cpu.run.summation", "cpu.usagemhz.average", "cpu.used.summation", "cpu.wait.summation", "mem.active.average", "mem.granted.average", "mem.latency.average", "mem.swapin.average", "mem.swapinRate.average", "mem.swapout.average", "mem.swapoutRate.average", "mem.usage.average", "mem.vmmemctl.average", "net.bytesRx.average", "net.bytesTx.average", "net.droppedRx.summation", "net.droppedTx.summation", "net.usage.average", "power.power.average", "virtualDisk.numberReadAveraged.average", "virtualDisk.numberWriteAveraged.average", "virtualDisk.read.average", "virtualDisk.readOIO.latest", "virtualDisk.throughput.usage.average", "virtualDisk.totalReadLatency.average", "virtualDisk.totalWriteLatency.average", "virtualDisk.write.average", "virtualDisk.writeOIO.latest", "sys.uptime.latest", ] # vm_metric_exclude = [] ## Nothing is excluded by default # vm_instances = true ## true by default # ## Hosts ## Typical host metrics (if omitted or empty, all metrics are collected) host_metric_include = [ "cpu.coreUtilization.average", "cpu.costop.summation", "cpu.demand.average", "cpu.idle.summation", "cpu.latency.average", "cpu.readiness.average", "cpu.ready.summation", "cpu.swapwait.summation", "cpu.usage.average", "cpu.usagemhz.average", "cpu.used.summation", "cpu.utilization.average", "cpu.wait.summation", "disk.deviceReadLatency.average", "disk.deviceWriteLatency.average", "disk.kernelReadLatency.average", "disk.kernelWriteLatency.average", "disk.numberReadAveraged.average", "disk.numberWriteAveraged.average", "disk.read.average", "disk.totalReadLatency.average", "disk.totalWriteLatency.average", "disk.write.average", "mem.active.average", "mem.latency.average", "mem.state.latest", "mem.swapin.average", "mem.swapinRate.average", "mem.swapout.average", "mem.swapoutRate.average", "mem.totalCapacity.average", "mem.usage.average", "mem.vmmemctl.average", "net.bytesRx.average", "net.bytesTx.average", "net.droppedRx.summation", "net.droppedTx.summation", "net.errorsRx.summation", "net.errorsTx.summation", "net.usage.average", "power.power.average", "storageAdapter.numberReadAveraged.average", "storageAdapter.numberWriteAveraged.average", "storageAdapter.read.average", "storageAdapter.write.average", "sys.uptime.latest", ] # host_metric_exclude = [] ## Nothing excluded by default # host_instances = true ## true by default # ## Clusters cluster_metric_include = [] ## if omitted or empty, all metrics are collected # cluster_metric_exclude = [] ## Nothing excluded by default # cluster_instances = false ## false by default # ## Datastores datastore_metric_include = [] ## if omitted or empty, all metrics are collected # datastore_metric_exclude = [] ## Nothing excluded by default # datastore_instances = false ## false by default for Datastores only # ## Datacenters datacenter_metric_include = [] ## if omitted or empty, all metrics are collected # datacenter_metric_exclude = [ "*" ] ## Datacenters are not collected by default. # datacenter_instances = false ## false by default for Datastores only # ## Plugin Settings ## separator character to use for measurement and field names (default: "_") # separator = "_" # ## number of objects to retreive per query for realtime resources (vms and hosts) ## set to 64 for vCenter 5.5 and 6.0 (default: 256) # max_query_objects = 256 # ## number of metrics to retreive per query for non-realtime resources (clusters and datastores) ## set to 64 for vCenter 5.5 and 6.0 (default: 256) # max_query_metrics = 256 # ## number of go routines to use for collection and discovery of objects and metrics # collect_concurrency = 1 # discover_concurrency = 1 # ## whether or not to force discovery of new objects on initial gather call before collecting metrics ## when true for large environments this may cause errors for time elapsed while collecting metrics ## when false (default) the first collection cycle may result in no or limited metrics while objects are discovered # force_discover_on_init = false # ## the interval before (re)discovering objects subject to metrics collection (default: 300s) # object_discovery_interval = "300s" # ## timeout applies to any of the api request made to vcenter # timeout = "60s" # ## Optional SSL Config # ssl_ca = "/path/to/cafile" # ssl_cert = "/path/to/certfile" # ssl_key = "/path/to/keyfile" ## Use SSL but skip chain & host verification insecure_skip_verify = true
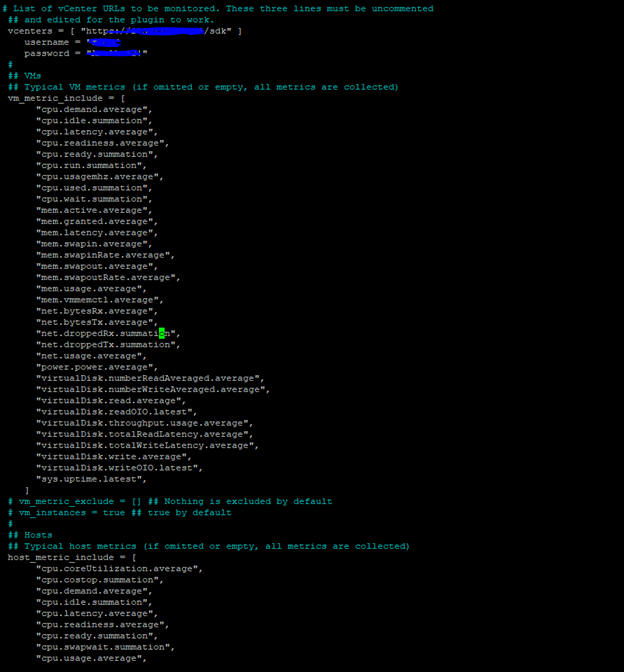
Çıkın ve kaydedin.
Telegraf restart edilir,
systemctl restart telegraf
Vmwarede ki değerleri ölçüm yapabiliyormuyuz test edelim.
influx -username 'monitoring' -password 'Password'
use vmware SHOW MEASUREMENTS
Aşağıdaki gibi çıktı gelecek,
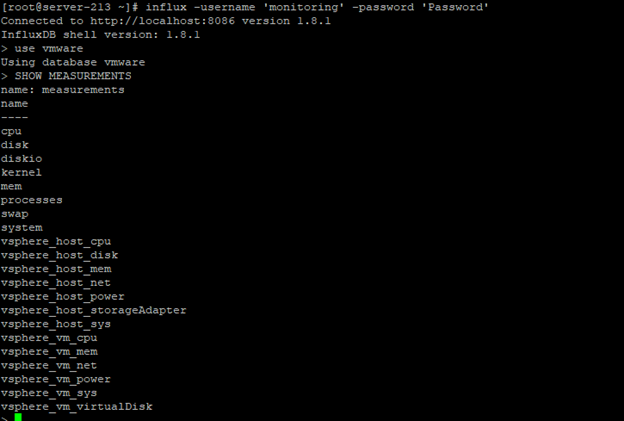
Herşey yolunda gözüküyor ardından değerleri daha anlamlı bir biçime getirmek için grafanaya aktaracağız,
Grafanaya login olalım configuration sekmesinden Add data sources seçelim,
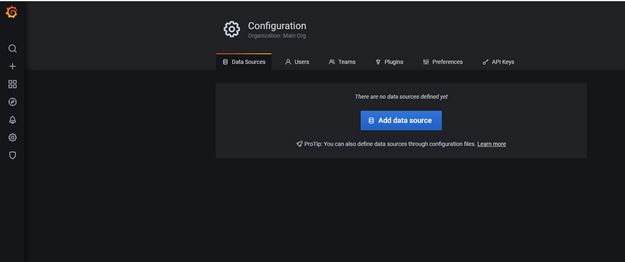
Influxdb seçelim,
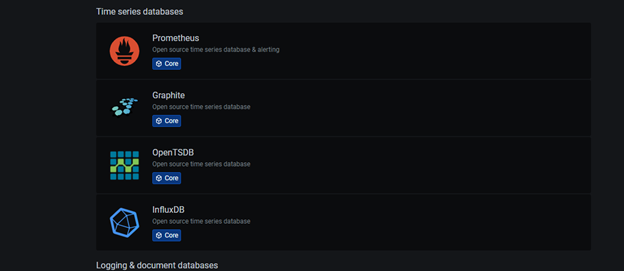
Bilgileri telegraf.conf içine girdiğimiz gibi girelim aynı şekilde,
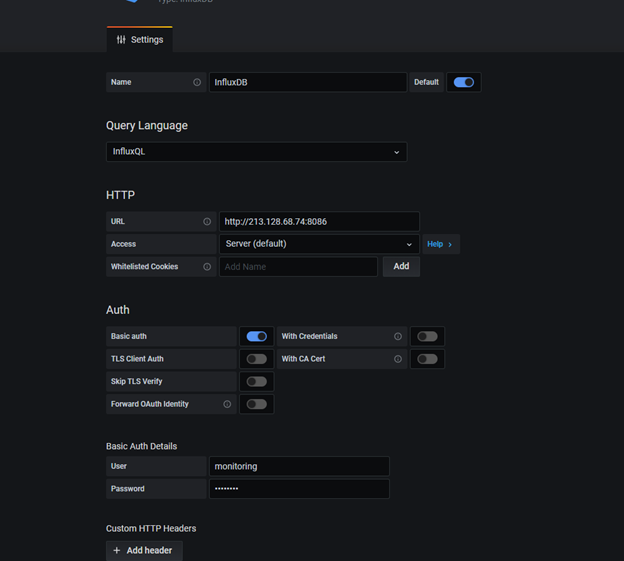
Save and test dediğimizde aşağıdaki gibi yeşil yanarsa herşey oke demektir,

Ardından anlamlı dashboardları eklemeye geldik,
Soldaki + işaretinden importa basıyoruz,
ID ekranına 8159 yazıp oke basıyoruz,yada 8165
https://grafana.com/grafana/dashboards/8159
Diğer dashboardlar için aşağıdaki linkleri kullanabilirsiniz,
https://grafana.com/grafana/dashboards/8162
https://grafana.com/grafana/dashboards/8165
https://grafana.com/grafana/dashboards/8168
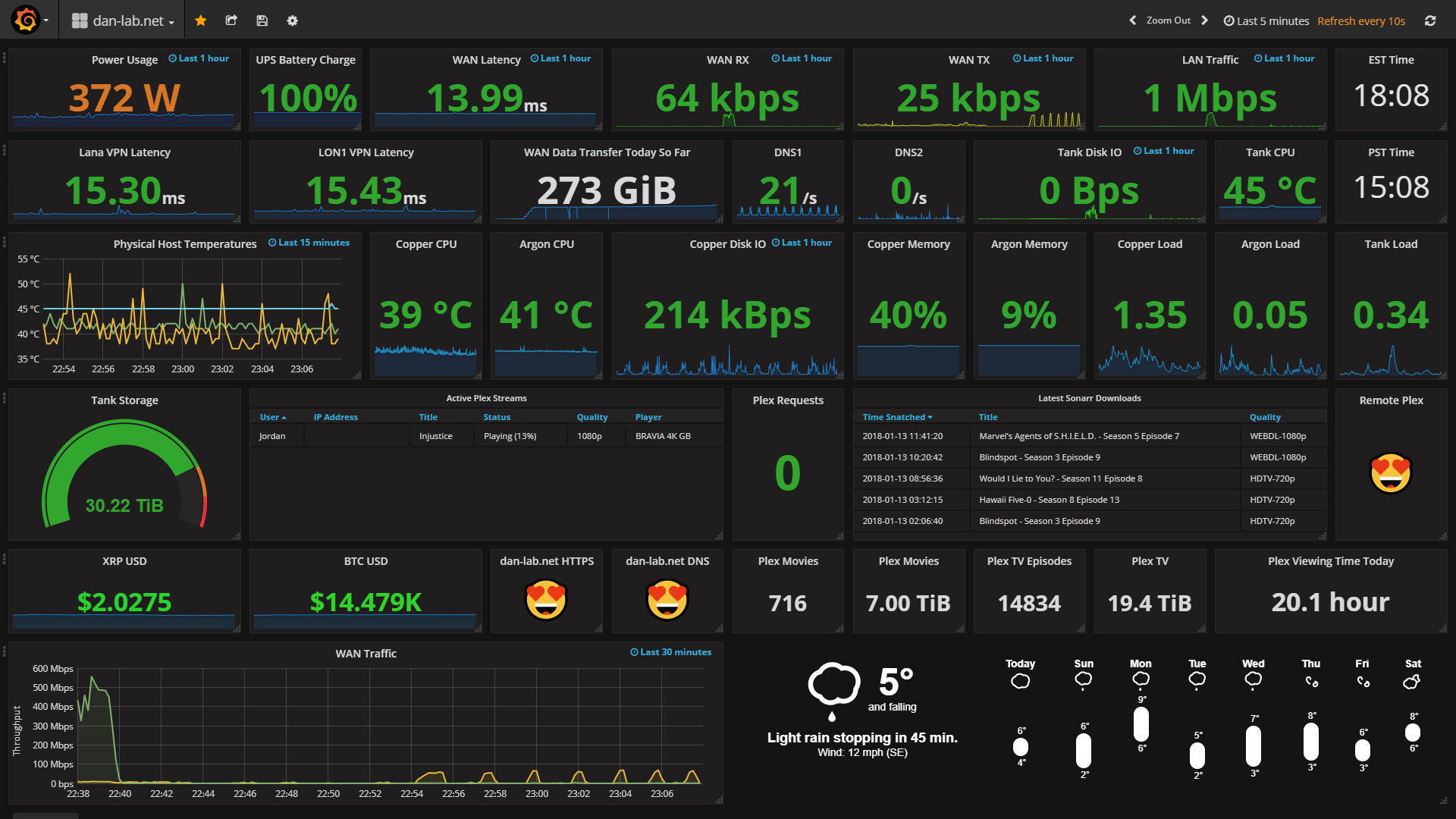
Metric değerleri aşağıdaki gibi karşımıza gelmeye başlıyor,
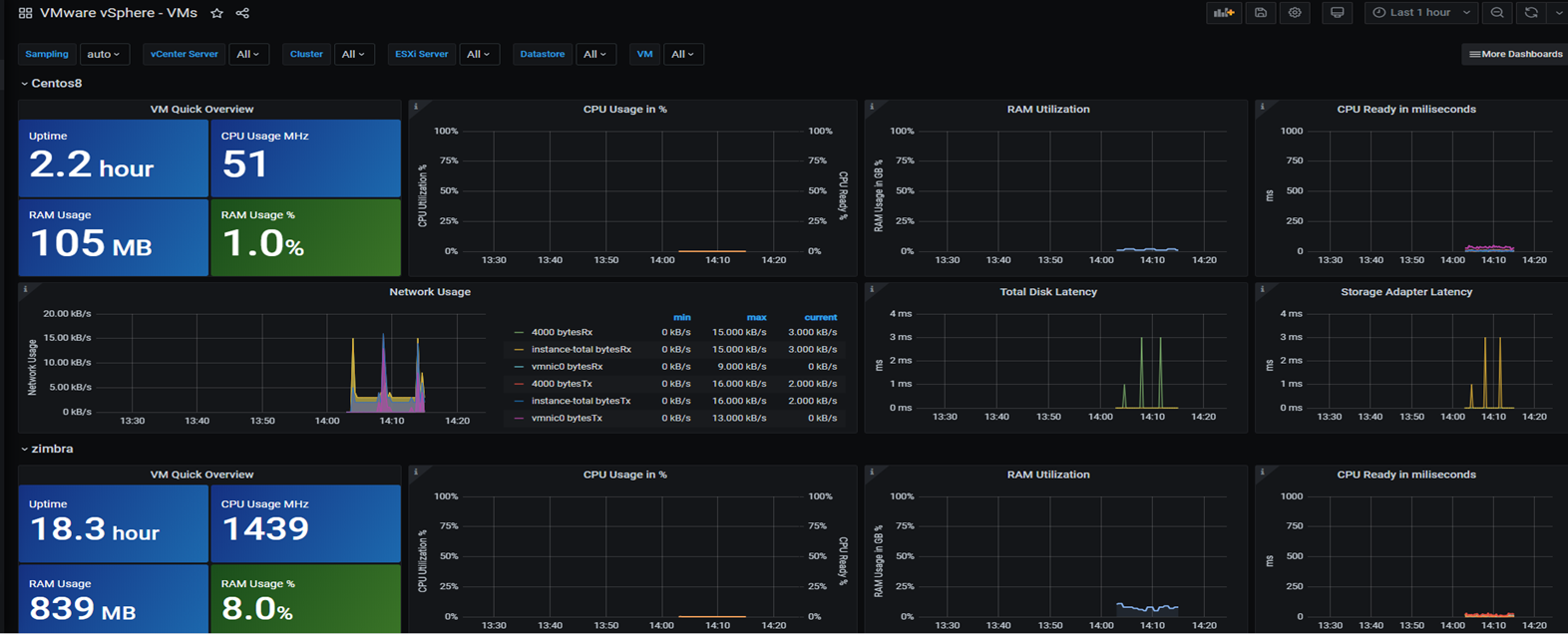
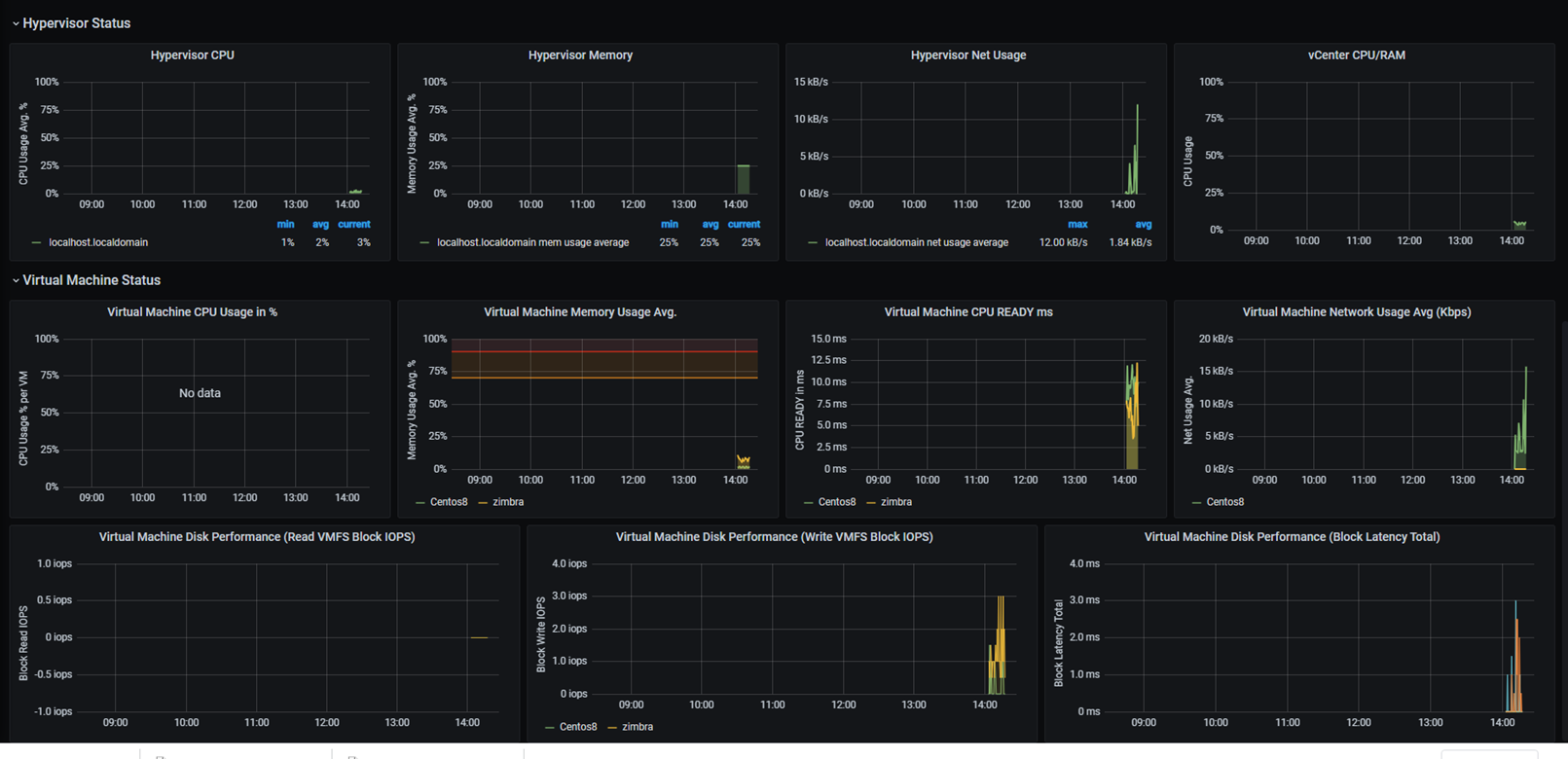
Bu yazımda daha önceki yazımın devamı olarak Grafana ile Vmware monitor edilmesini kısaca özetlemeye çalıştım. Grafana ayarları ile daha ince detaylı grafikler elde edebiliriz. Ben hazır şablonlar üstünden izlemeyi anlattım.
Bu konuyla ilgili sorularınızı alt kısımda bulunan yorumlar alanını kullanarak sorabilirsiniz.
Referanslar:
www.mshowto.org
TAGs:Garafana monitor vmware , vcenter monitor free tool, grafana monitoring, vmware için monitoring